经过一年的忙碌,兆松科技研发的RISC-V zcc编译器2.0版本正式发布,目前国内外各大主流RISC-V芯片/IP公司正在合作评估中,欢迎有兴趣的小伙伴随时勾搭。
废话不多说,下面主要展现一下2.0版本当中的改进。
SPECINT2K6
SPECINT2K6动态指令数,比riscv gcc 12.2好14%,比llvm16好15%,比美国某RISC-V IP公司商业化编译器好10%-15%
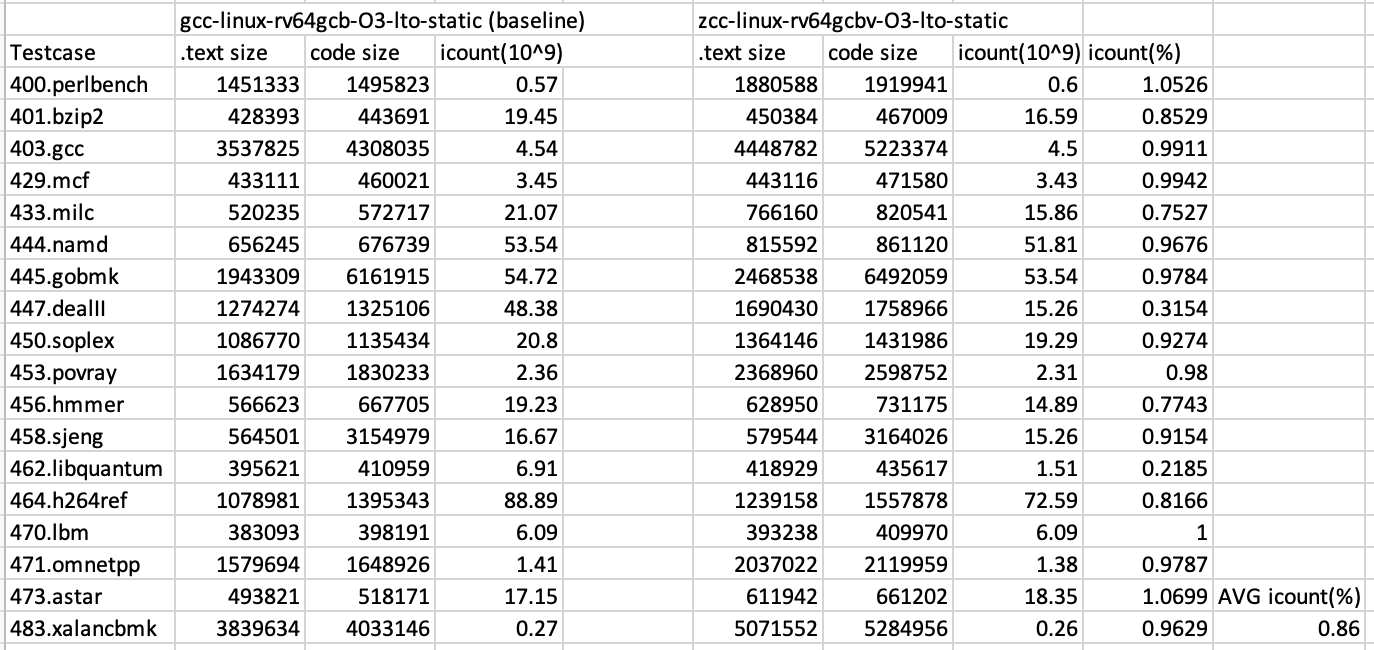
注:由于gcc RVV自动向量化无法成功编译一些SPECINT2K6的测试,故以上数据仅为gcc rv64gcb。
注:以上icount数据为SPECINT2K6 small dataset测试所得动态指令数, 数据越小越好。
注:美国某RISC-V商业公司编译器数据由多伦多某著名RISC-V芯片公司协助评估提供。
RVV自动向量化
zcc自动向量化器可以产生比手写intrinsic算子库更好的性能(平均10%以上的性能优势),比gcc12-rvv-next自动向量化器最多快70倍,比llvm 16自动向量化器最多快86倍。(在我们测试的时候,以下有一些例子,gcc12-rvv-next,以及llvm16还无法成功做到多层循环的自动向量化)。
在#pragma的帮助下,zcc可以实现任意嵌套层次循环的自动向量化,可以解决最内层循环自动向量化的一些访存问题,从而让性能大幅提升。从我们合作评估方的反馈数据得知,zcc自动向量化的correlation算子的cycle数,比手写intrinsic版本的correlation算子cycle数好50%(cache命中显著提升)。
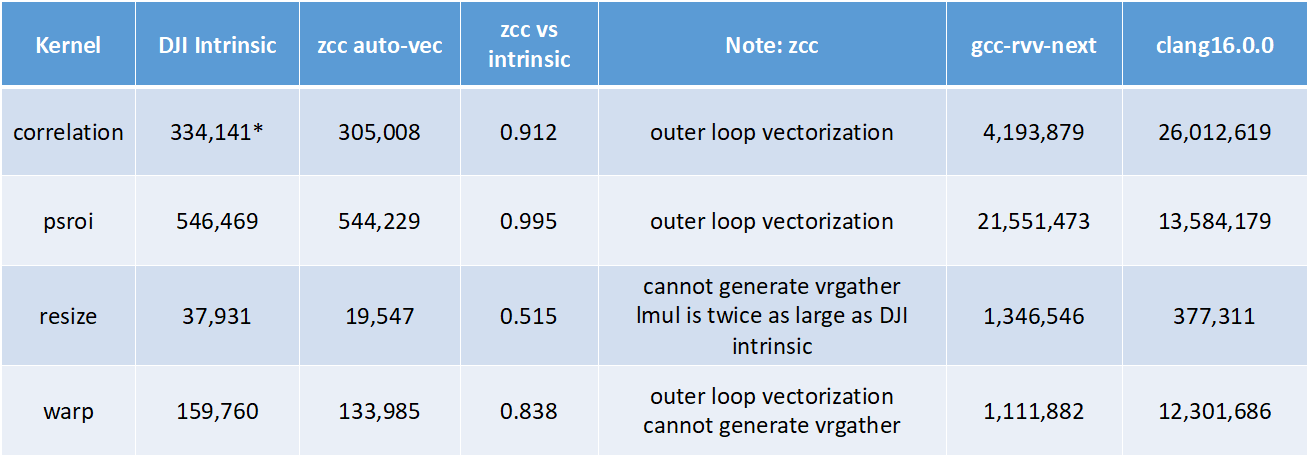
注:以上kernel源代码和intrinsic代码,可在https://github.com/tristanqiu8/rv_lib下载
注:自动向量化测试数据使用clang #pragma辅助
代码密度优势
除了上面提到的性能优势,我们zcc编译器在1.0版本的基础上,继续保持着代码密度优势,在embench-iot测试当中,.text段代码密度平均比gcc12.0好25%左右。
欢迎小伙伴前来索取试用评估版本的工具链(aries.wu@terapines.com)