本来想取一个爆炸的标题《可能是全球范围内最好的RISC-V Vector自动向量化器的实现》,但是本着科学严谨的态度,以及对未知事物的敬畏,还是取了这个没有吸引力的标题,这样即使被打脸了,也还有挽回的余地。
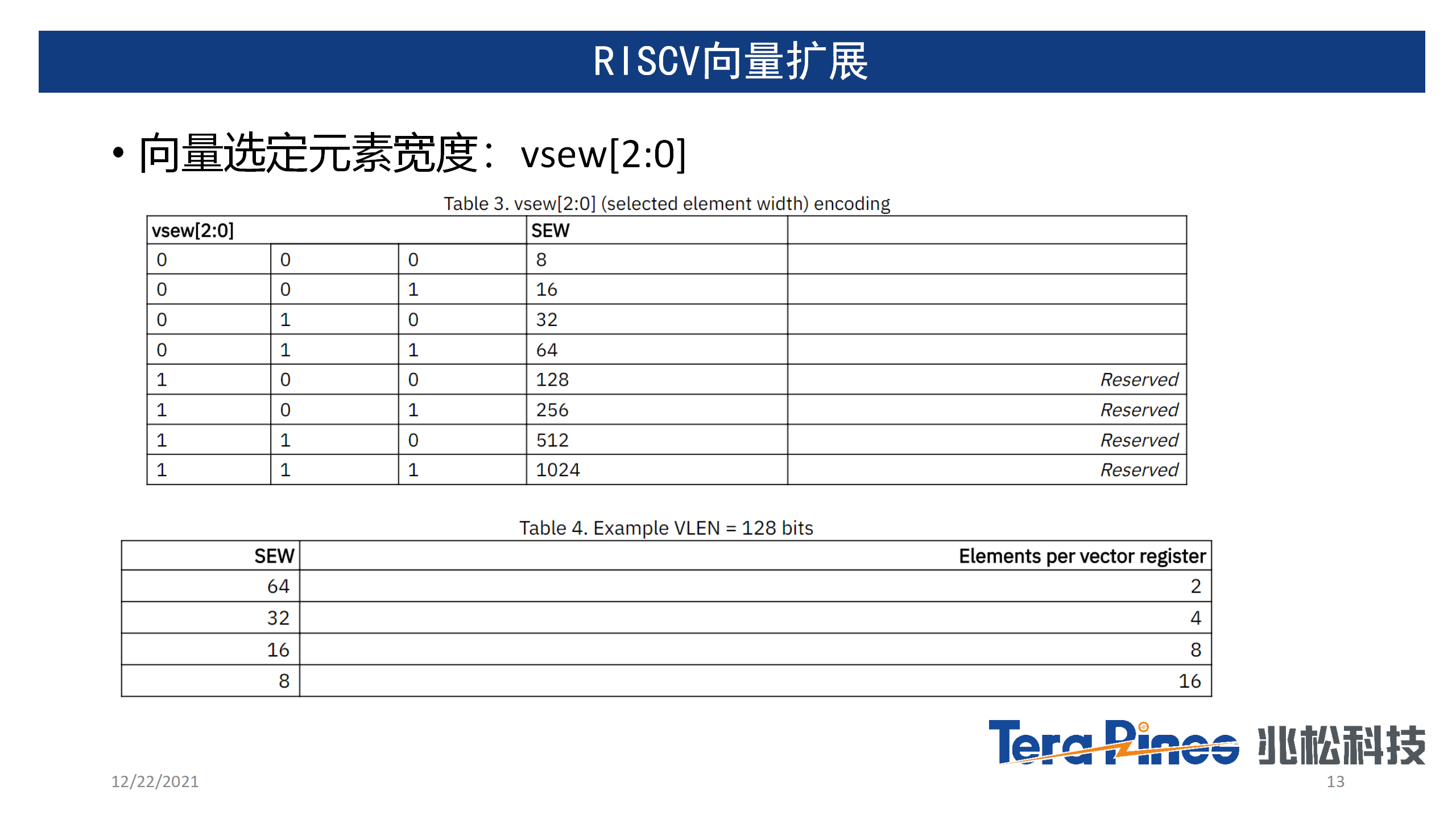
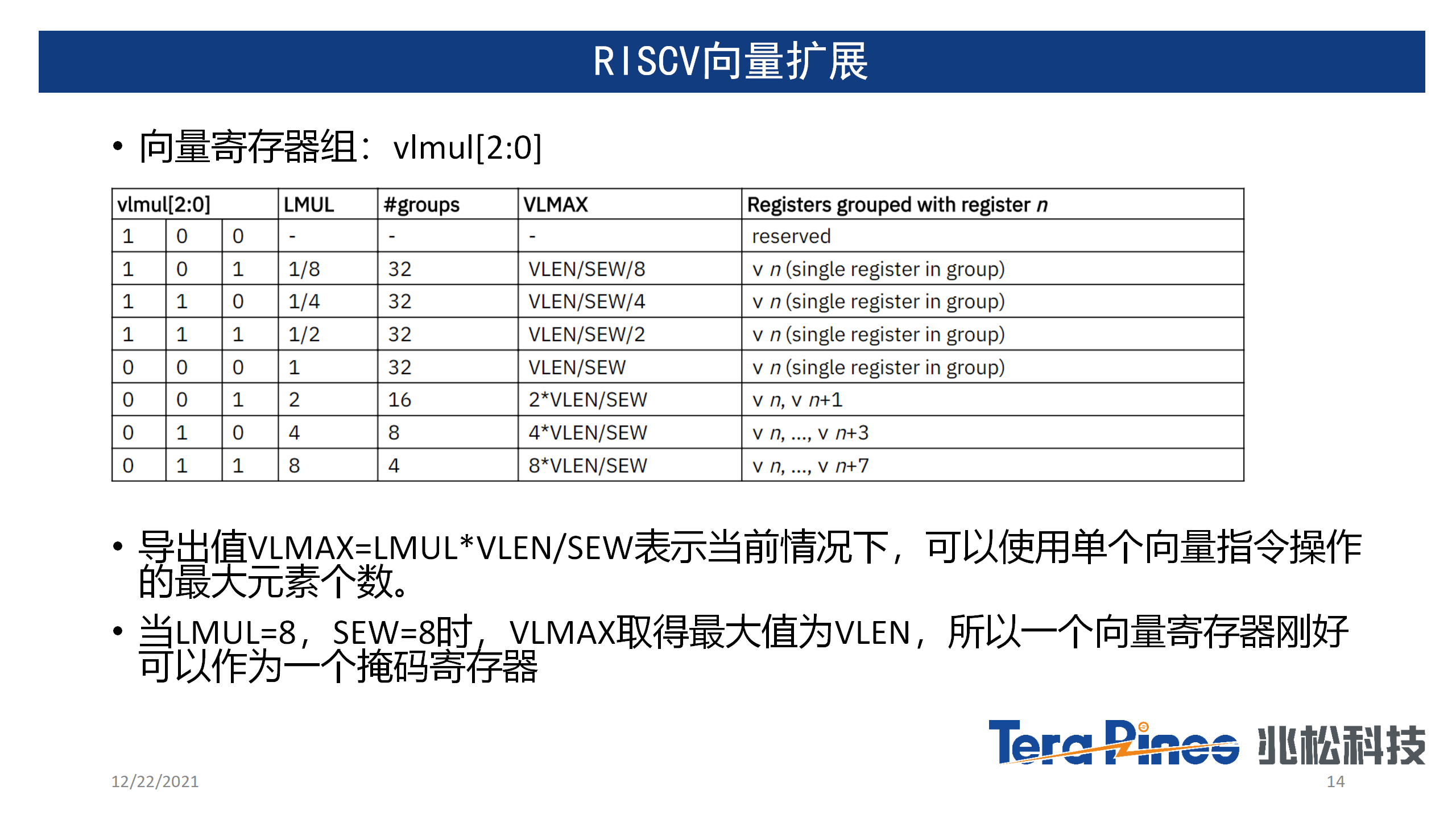
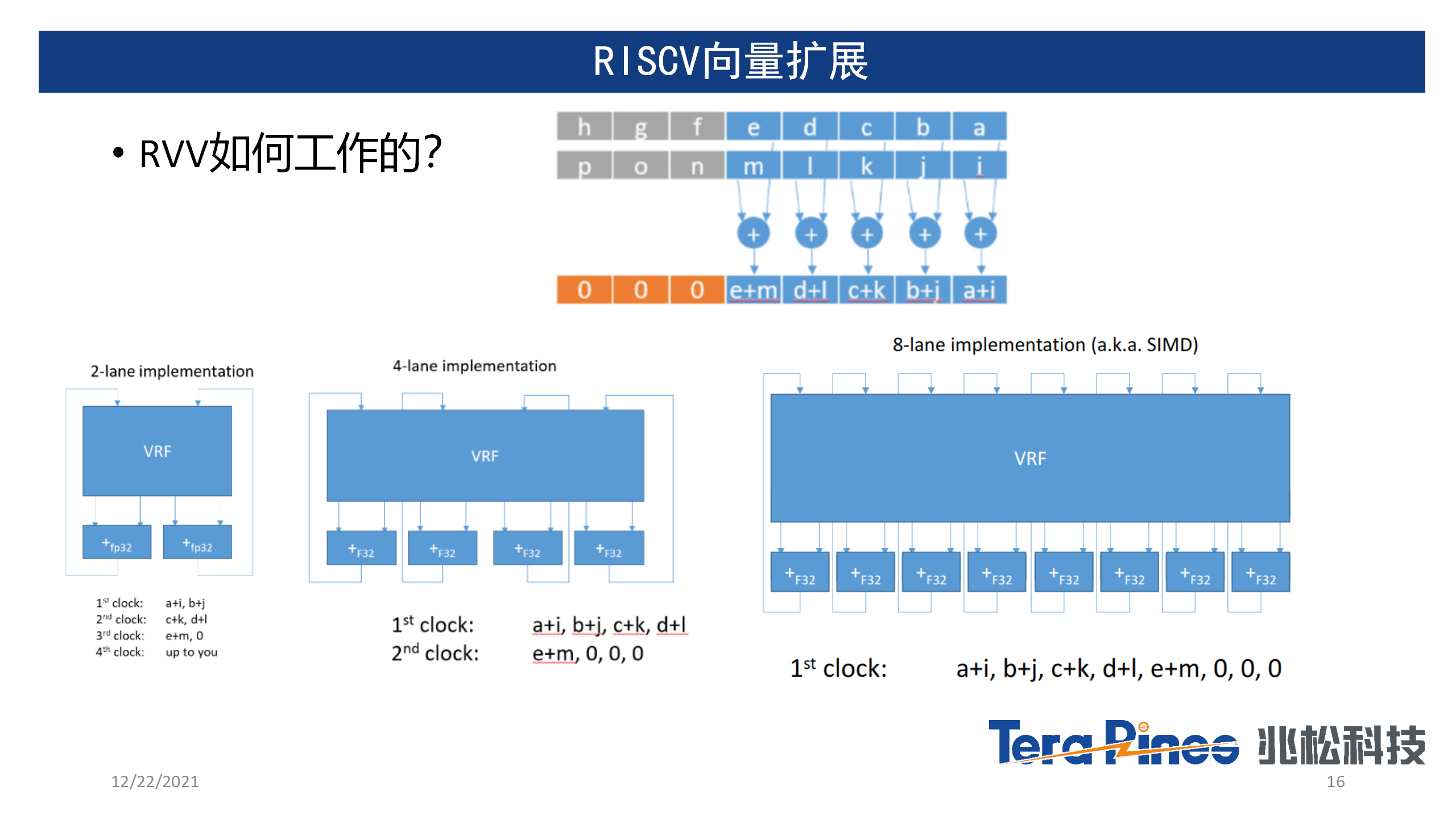
RISC-V Vector与目前市面上大部分SIMD的向量指令集是不同的,它有点类似于ARM的SVE和SVE2可变长向量指令,但又不完全一样。比如在ARM中SVE/SVE2变长向量指令集可以在程序启动的时候配置向量寄存器大小,运行时动态设置元素宽度,而RISC-V Vector扩展更加灵活,可以使用vsetvl指令,在运行时动态调整寄存器大小,组数,元素数据宽度,以及掩码操作等等。这样的架构对于指令集来说好处是解决了对未来的兼容性,并且可以让同一份可执行文件,在不同架构的向量处理器中充分利用各种不同宽度的向量处理器,实现一份代码,兼容不同硬件架构,从而大大降低了软件的维护成本。
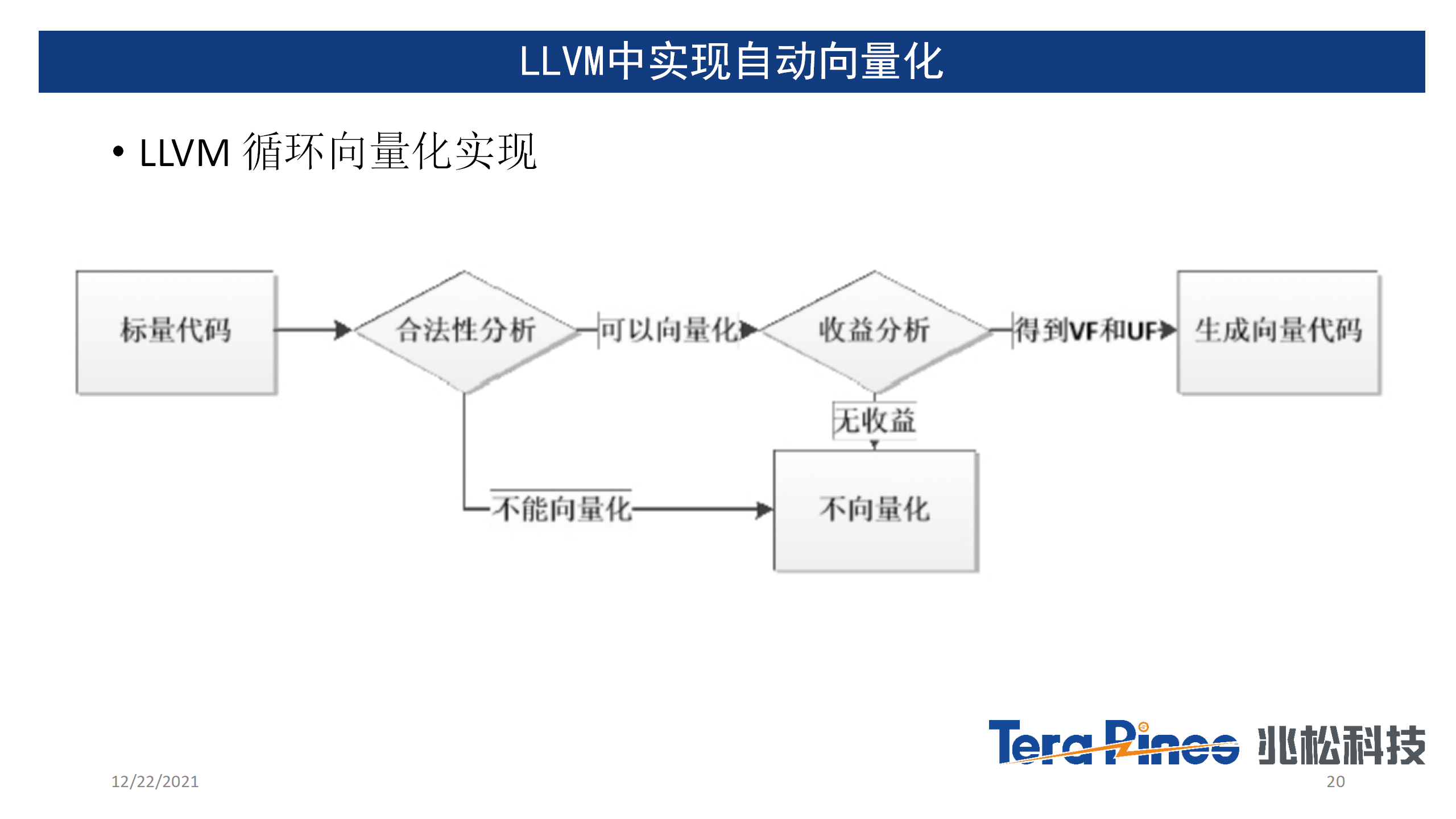
不过,由于目前主流的编译器框架llvm,gcc只支持SIMD类型的自动向量化,EPI(European Processor Initiative 欧洲超算中心的一个项目)虽然基于llvm做了一些初步的RISC-V可变长自动向量化的工作,但是实现的非常粗糙,并且产生的RVV代码质量比较差。据悉,目前上游RISC-V相关的维护团队已经放弃了在gcc当中实现RVV自动向量化的想法,llvm上游也迟迟未动工。
所以兆松科技基于llvm框架,实现了一套高质量的RVV自动向量化器。据当下可获取的信息,可以说我们实现的自动向量化器,是目前业内最完整,质量最好的自动向量化器。目前使用zcc编译我们自研的DSP函数库,大部分循环均可以产生高质量的RVV指令,对于一些更复杂的循环,我们也正在研发更好的自动向量化机制,目标是降低高性能函数库优化的门槛,坚决避免手撸RVV intrinsic甚至手撸汇编,提高底层函数库的可移植性以及降低函数库的维护成本。
文后提供了兆松团队成员晏明参加OSDT2021的视频和PPT,其中包括zcc编译器当中所实现的RVV自动向量化器,以及对RVV架构的简介,横向对比了EPI以及llvm上游的实现质量(其实上游只对RVV简单的做了一些intrinsics实现而已)。
OSDTConf2021视频:
OSDTConf2021演示文稿:



































Pingback: 地表最强: 最高90%代码密度优化,64%性能提升,兆松RISC-V工具链正式发布 – 兆松科技